Build a reproducible workflow¶
Create a workflow step¶
Now we will use renku to create a reproducible, reusable “workflow”. A
workflow consists of a series of steps, each of which may consume some input
files, execute code, and produce output files. The outputs of one step are
frequently the inputs of another — this creates a dependency between the code
execution and results. When workflows become more complex, the bookkeeping can
be tedious. That is where Renku comes in — it is designed to keep
track of these dependencies for you. We will illustrate some of these concepts
with a simple example (see also the Provenance of results in the documentation).
First, let us make sure the project repository is clean. Run:
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
nothing to commit, working directory clean
Make sure the output ends with nothing to commit, working tree clean.
Otherwise, you have to clean up your project repository by either removing
the changes or committing them to the repository.
Note
You can undo your changes with:
$ git checkout .
$ git clean -fd
Or, if you want to keep your changes, commit with:
$ renku save -m "My own changes"
The filter_flights.\* script takes two input parameters:
a file to process as an input
a path for storing the output.
So to run it, we would normally execute the following:
# Here for comparison -- do not run these lines
$ # mkdir -p data/output
$ # python src/filter_flights.py data/flight-data/2019-01-flights.csv.zip data/output/flights-filtered.csv
# Here for comparison -- do not run these lines
$ # julia src/FilterFlights.jl data/flight-data/2019-01-flights.csv.zip data/output/flights-filtered.csv
# Here for comparison -- do not run these lines
$ # Rscript src/RunFilterFlights.R data/flight-data/2019-01-flights.csv.zip data/output/flights-filtered.csv
For renku to capture information about the execution, we need to make a small
change: we prepend renku run to relevant command:
# Create the output directory
$ mkdir -p data/output
$ renku run --name filter-flights -- python src/filter_flights.py data/flight-data/2019-01-flights.csv.zip data/output/flights-filtered.csv
Info: Adding these files to Git LFS:
data/output/flights-filtered.csv
$ renku run --name filter-flights -- julia src/FilterFlights.jl data/flight-data/2019-01-flights.csv.zip data/output/flights-filtered.csv
Info: Adding these files to Git LFS:
data/output/flights-filtered.csv
$ renku run --name filter-flights -- Rscript src/RunFilterFlights.R data/flight-data/2019-01-flights.csv.zip data/output/flights-filtered.csv
Info: Adding these files to Git LFS:
data/output/flights-filtered.csv
Go ahead and run this command: it will create the preprocessed data file,
including the specification of how this file was created, and commit all the
changes to the repository. The --name option allows you to name the
workflow that’s created by renku run to make it easier to reuse it later.
Workflows created in this way don’t just try past executions, but also define
workflow templates (Called Plans in Renku) that can be executed with
arbitrary parameters on different workflow backends and exported to other
workflow languages.
See the renku command line docs
for more information on this and other commands.
Note
Did you accidentally run the plain Python, Julia or R command first? You would get an error like this
Error: The repository is dirty. Please use the "git" command to clean it.
On branch master
Your branch is up to date with 'origin/master'.
Untracked files:
(use "git add <file>..." to include in what will be committed)
data/output/
Remove the untracked files and this time execute only the renku command
$ rm data/output/*
$ renku run --name filter-flights -- X src/filterFlights.X data/flight-data/2019-01-flights.csv.zip data/output/flights-filtered.csv
where X stands for the particular language you are using.
Note
Did you get an error like this instead?
Traceback (most recent call last):
File "src/filter_flights.py", line 26, in <module>
df.to_csv(output_path, index=False)
File "/opt/conda/lib/python3.7/site-packages/pandas/core/generic.py", line 3228, in to_csv
formatter.save()
File "/opt/conda/lib/python3.7/site-packages/pandas/io/formats/csvs.py", line 183, in save
compression=self.compression,
File "/opt/conda/lib/python3.7/site-packages/pandas/io/common.py", line 399, in _get_handle
f = open(path_or_buf, mode, encoding=encoding, newline="")
FileNotFoundError: [Errno 2] No such file or directory: 'data/output/flights-filtered.csv'
Error: Command returned non-zero exit status 1.
If in the process of working through the tutorial, you stopped the session and started a new one along the way, this may happen. Why? Under the hood, we use git-lfs to save large files, and these files may not be fetched when a new environment is started. We try to retrieve them automatically when needed for a Renku command, but that may not always work.
If you check the data/flight-data/2019-01-flights.csv.zip file you
will see only a few lines of metadata starting with
version https://git-lfs.github.com/spec/v1. You can easily
fetch the data manually from the console by running
$ git lfs pull
Downloading LFS objects: 100% (1/1), 66MB | 22 MB/s
Another way to verify that your lfs files have been fetched is running the
ls-files command and check if every file has a “*” (pulled) or a “-”
(not pulled)
$ git lfs ls-files
2b1851ab60 * data/flight-data/2019-01-flights.csv.zip
Warning
Do not make any edits to the code before the renku run
command is finished. In order to keep track of the outputs of
your script, Renku will automatically add the changes to
git. If you want to modify your project while a renku command
is executing, you should create a new branch.
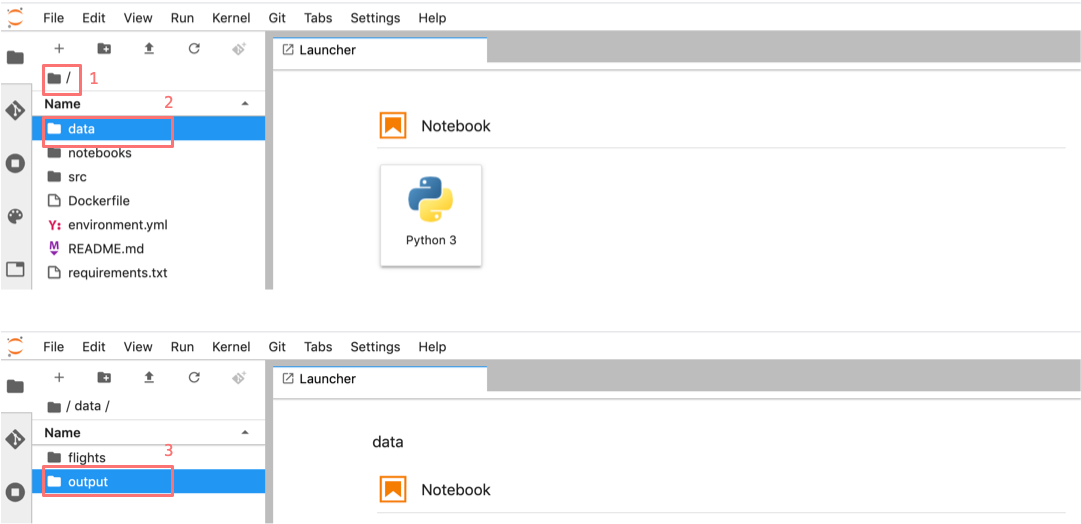
Aside: looking at data in JupyterLab
The original zip file is not easy to visualize in Jupyter,
but the csv output of filtering can be opened from JupyterLab by navigating to
the File tab on the top left (1), then clicking data
folder (2) and output (3).
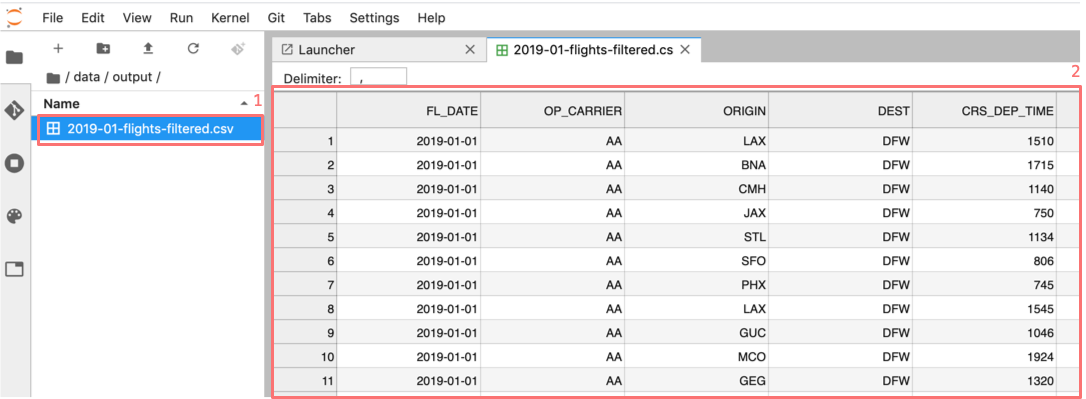
Opening the file
flights-filtered.csv (1),
we can see its contents (2).
Add a second workflow step¶
We will now use a second script to count the flights in the filtered data file. As before, we will fast-forward through this step by downloading the solution.
The respective interactive versions can be found below and you can copy them
to your project as before if you wish to play with the data interactively.
We also provide the script versions to be run with the renku run command.
For the next step you must download the script from here,
and then drop it into the src directory as with the filter_flights.py script.
Download Julia script
and drop it in the src directory.
Download R script,
and drop it in the src directory.
After uploading the script to your project, make sure you save your work:
$ renku save -m 'added the script to count flights'
Now we are ready to create a second step of our workflow. First, make sure your repository is “clean”:
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
nothing to commit, working directory clean
If the output does not end with nothing to commit, working tree clean,
cleanup the project repository by either removing the changes or
committing them.
Note
You can undo your changes with:
git checkout .
git clean -fd
Or, if you want to keep your changes, commit with:
$ renku save
We can now use renku run to generate the second step of our workflow:
$ renku run --name count-flights -- python src/count_flights.py data/output/flights-filtered.csv data/output/flights-count.txt
There were 23078 flights to Austin, TX in Jan 2019.
$ renku save
$ renku run --name count-flights -- julia src/CountFlights.jl data/output/flights-filtered.csv data/output/flights-count.txt
There were 23078 flights to Austin, TX in Jan 2019.
$ renku save
$ renku run --name count-flights -- Rscript src/CountFlights.R data/output/flights-filtered.csv data/output/flights-count.txt
There were 23078 flights to Austin, TX in Jan 2019.
$ renku save